What’s new in v0.177.0?
Covalent version 0.177.0 is now live!
In this release, users can now define custom hooks for installing and managing software environments, while also defining data dependencies among tasks. We’ve also made some significant changes to the core of the dispatcher service. In v0.110.2 and earlier, we transferred information using a single source of truth called the Result object. Although this was convenient for development, it meant that we had to move, pack, and unpack a bulky pickled object at many points throughout a workflow. Moving forward, we have moved to a robust SQL database which now contains all attributes inside the Result object. This design enhancement has lead to tremendous improvements in speed as well as stability. Together with these backend changes, we have also introduced many UI improvements and an updated theme. See if you notice the difference!
See the full list of new features included in v0.177.0 in the table below:
| Features | Summary |
|---|---|
| Dependencies | Users can now have pre- and post- hooks for electrons running on remote machines. This helps in a variety of ways, from setting up remote environments to managing consistent execution. |
| File transfers | Covalent now natively supports a very modular file transfer mechanism between local and remote file systems. Protocols include Rsync, HTTP, and AWS S3. |
| User interface (theme + improvements) | The UI now includes a theme that is consistent with the theme we introduced for Covalent in the previous release. Along with this, there is a multitude of new improvements that make the UI faster, better and more visually appealing. |
| New and improved database | The Covalent server now uses a new and improved database that makes Covalent much faster and more stable, especially for large workflows. |
🪝Dependencies (Deps): For all the times you needed hooks
For a thorough discussion on why and how we made this choice, please check out (or participate in) our GitHub discussion on the topic.
One of the core functionalities of Covalent is the ability to execute high performance code on diverse hardwares paradigms. This inherently dictates the need to control various aspects of execution environments, which we call “Dependencies” because the execution of an electron depends on it. To this end, we introduce the concept of Deps , short for Dependencies. To start with, in this release we introduce three main abstractions for Deps:
DepsBash– This is a helper abstraction that allows users to execute arbitrary bash commands before or after the execution of an electron. A typical use case for this would be downloading a git package,make-ing a program before execution, saving secrets or environment variables, etc. Example:DepsBash(["echo $PATH","ssh foo@bar.com"])DepsPip– This is a helper abstraction for installing Python packages. This is extremely useful in the case of cloud execution where one is often given a bare metal machine without any pre-installed packages. Example:DepsPip(packages=["numpy==0.23","qiskit"])or even add a requirement fileDepsPip(reqs_path="./requirements_example.txt")DepsCall– Although we provide convenient hooks for running custom bash and pip commands, there is always a use case for more generic hooks. This class gives users the ability to execute arbitrary Python functional calls before and after the task execution. ExampleDepsCall(execute_before_electron, args=(1, 2))), whereexecute_before_electronis a Python function that takes in theargsas arguments.
We implemented a straightforward UX to call Deps before and after execution – for example, one can do the following:
import covalent as ct
def shutdown_after_electron():
'''shut down my remote machine'''
pass
deps_pip=ct.DepsPip(packages=["numpy==0.23", "qiskit"]),
deps_bash=ct.DepsBash(commands=["echo $PATH"])
@ct.electron(
deps_pip=deps_pip,
call_before=[deps_pip, deps_bash],#Re-runing pip installation
call_after=ct.DepsCall(shutdown_after_electron),
)
def identity(x):
return x
To learn more about how to use Deps, take a look at the How-To Guides.
📂 File transfers : Moving your files has never been easier
For a thorough discussion on why and how we made the choice, please take a look at (or participate in) our GitHub discussion on the topic.
Transferring files before or after execution can be a huge challenge, especially when one needs to connect to various remote hardware. Users now have access to an abstracted method that takes care of this. These file transfer operations can be performed by specifying a list of FileTransferinstances (along with a corresponding File Transfer Strategy) in an electron’s decorator using the files keyword argument. File transfer operations are queued to execute prior or post electron execution in the electron’s backend execution environment.
It is designed in an extremely modular way that enables users to either transfer files (ct.File) or folders (ct.Folders) or simply pass the path to the transfer method as ct.fs.FileTransfer('src_file','dest_file'). By default, the file transfer will occur prior to electron execution; however, one can specify that this should be performed post execution using the Order enum such as: ct.fs.FileTransfer('src_file','dest_file', order=ct.fs.Order.AFTER). The same is true for folders. Additionally, to make things even more modular, users can also define a strategy to transfer the files. We currently include Rsync , HTTP, and S3 strategies out of the box, with more coming soon. To transfer files from S3, its as simple as:
import covalent as ct
strategy= ct.fs_strategies.S3(credentials='/home/user/.aws/credentials')
ct.fs.FileTransfer('s3://my-bucket/temp.txt','~/temp.txt', strategy=strategy)
To know more about file transfers, take a look at the How-To Guide.
✨ A new theme and revamped UI
We made some minor modifications to the look and feel of the UI which you can see on our demo website here: http://demo.covalent.xyz/.
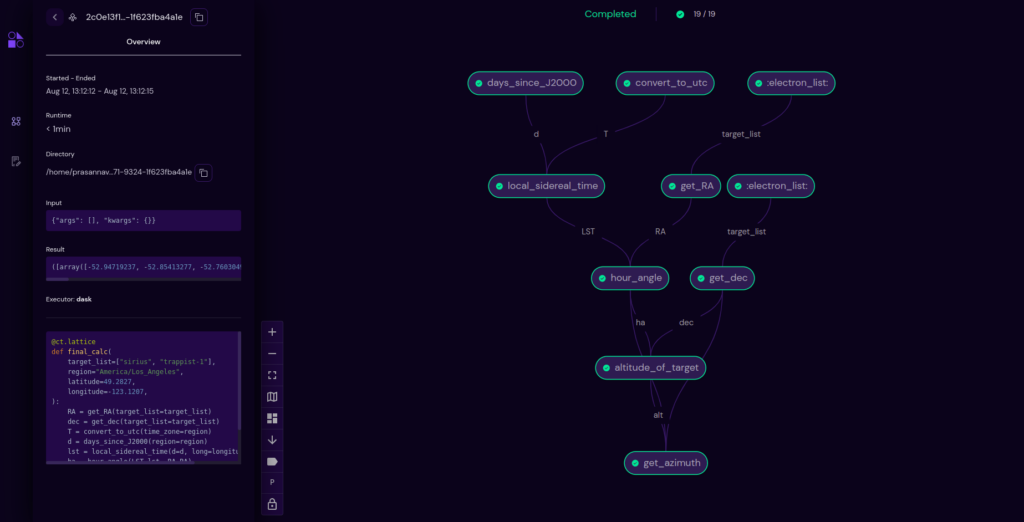
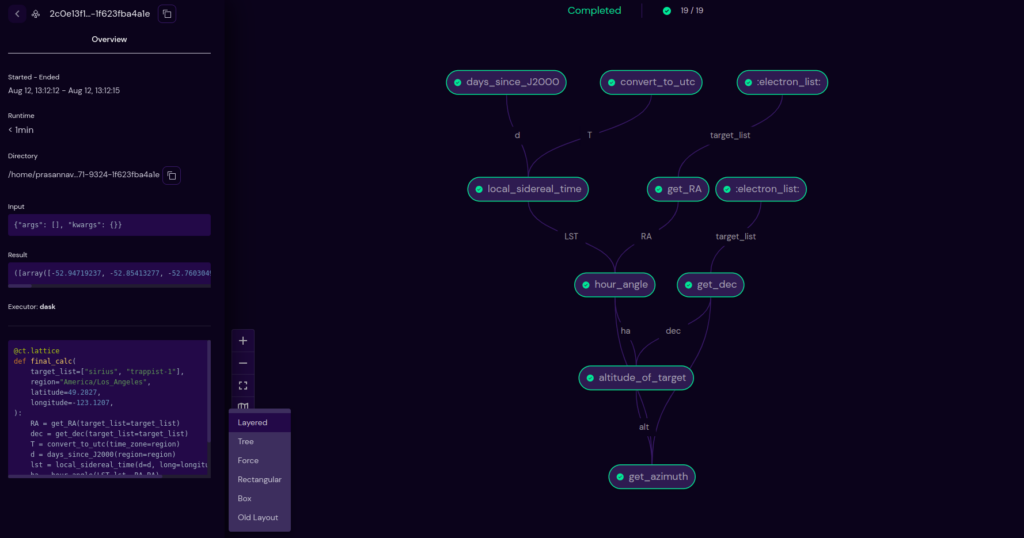
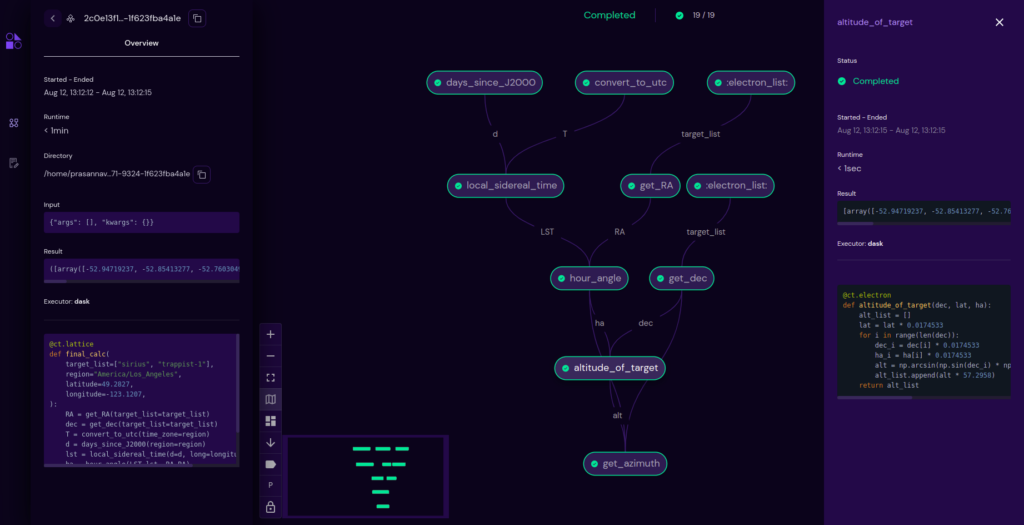
Graph layout enhancements: layout + toggles
Layout options
In this release, users have the ability to choose the layout view of the transport graph from various layout options.
This gives the user control over the graph and lets them choose the appropriate layout for their workflow. The new layout implementation can also accommodate graphs with a large number of nodes (even 100 nodes), and allows them to see it as a whole in one view.
Note: The old layout engine has been retained as one of the options to provide users continuity and enable a smooth transition from the old to the new layouts.

Toggle labels
Users also now have the ability to toggle show/hide labels. This has been added to present a more concise graph UI when labels are irrelevant in a workflow.
Optimization of live refresh
The graph & data live refresh scenarios have been optimized by tweaking the websocket and API implementation in the UI. Users now experience a better UI performance in general as a result of these optimizations.
A few specific scenarios have been optimized:
- Live refresh of the graph only when relevant and necessary. For instance, if a user is viewing workflow B while workflow A receives a status update, no refresh is performed.
- If a user is on the graph page and a workflow receives a status updates, the dispatch list data will not be refreshed. The dispatch list will be refreshed only if the user is on the dashboard.
- API calls from the UI have also been throttled by time to ensure that a data update is performed once every few seconds and not multiple times every second.
Pagination
The look and feel of the pagination feature on the dispatch list view has been modified and made more user friendly, with only 10 records displayed on the page at a time. The user has the ability to go to the next page and previous page as well as to the first and last page.
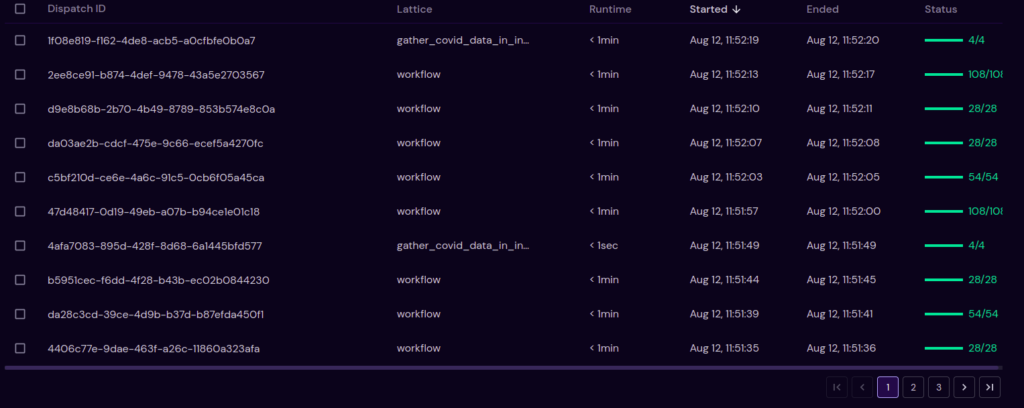
Interactive tooltips for long words
Tooltips have been added for long words on the dispatch list view for enhancing user experience and making the page more user-friendly.
Placement of lattice status and completion status
The statuses have been moved to the top of the graph for better look and feel of the graph view.
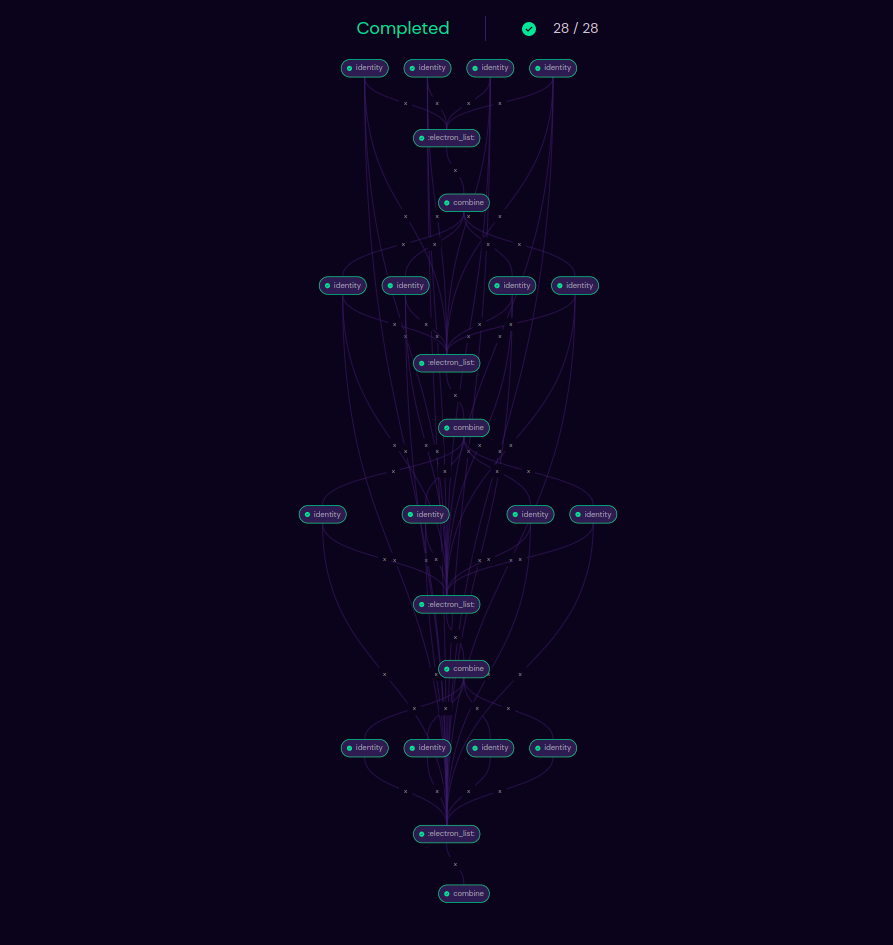
Placement of minimap
The minimap has now been moved closer to the graph controls for better viewing and accessibility, as opposed to the earlier version where it was placed on the right of the graph and gets hidden when the electron sidebar is opened.
🗃️ Database for the win
For a thorough discussion on why and how we made the choice, please take a look at (or participate in) our GitHub discussion on the topic.
The way in which workflow results are stored and shared has been redesigned from the ground up. We have removed the concept of the “results directory” and transitioned to use a database for storing and retrieving all information from dispatches to lattice graphs. This affects both the way the frontend UI works as well as how the backend works, and also has a few additional implications:
- What used to be a direct read from the unpickled Python objects by the frontend is now a read operation from the database.
- In the backend, we no longer pickle and unpickle any Pythonic workflow information except on the client side and on the execution side. This tremendously reduces Covalent’s overhead (by nearly 300% for large 80-100 node graphs and by Kbs of intermediate data)
- The user no longer has access to
results_directorythat was generated after each run in their local execution. This was designed in the early stages of Covalent, keeping in mind that we were soon going to transition to a database query so that Covalent can be self-hosted remotely.
Although the schema for how exactly we are storing these data is continuously evolving, we have found a stable point which gives us the right amount of optimization for now. We have solved a lot of interesting problems – and for the curious, we will soon share all the details in a subsequent post.
Contributors
This release would not have been possible without the hard work of the team at Agnostiq and our contributors: @AgnostiqHQ , @mshkanth, @Prasy12, @amalanpsiog, @Socrates