What is Covalent?
Modern machine learning research and development is hard, and not for the reasons you might expect. While a researchers’ primary focus is to identify novel learning models and understand various tricks to help them train more efficiently, it is increasingly common for them to spend a significant portion of their time on operations. This adjacent field of work — machine learning operations (MLOps) — addresses the practical challenges associated with designing, scaling, and distributing machine learning experiments in increasingly heterogeneous environments. Both cloud and multi-cloud machine learning are becoming more common, especially among small and medium sized organizations without traditional on-prem infrastructure. These organizations need suitable MLOps tools to ensure their researchers remain focused on novel research rather than undifferentiated operations.
Covalent is a workflow orchestration platform specifically designed for research and development with custom high-performance computing requirements. Machine learning practitioners often find themselves performing similar sets of interdependent tasks — workflows — over and over; for instance, one might select a model, pre-process data, train and test a model, perform some post-processing and analysis, and then repeat the entire process while iterating over different models, hyperparameters, and compute backends. Covalent allows users to manage such experiments and their revisions by collecting metadata and visualizing it for users on a rich browser-based user interface. Moreover, with minimal code changes — just one line of code per function — users can transition from a local prototype running on a laptop to an application running at scale in a hybrid or multicloud configuration. Covalent supports a variety of cloud-based compute backends on the most popular cloud platforms, including Kubernetes and Batch, which enables teams to flexibly deploy portions of their code to the most available and least expensive computers, wherever they reside.
Constructing Workflows with Electron and Lattice Decorators
Let’s dig a little deeper into what Covalent offers. In these examples, we’ll use simplified functions, but keep in mind any of these tasks can utilize the most popular machine learning toolkits. Given a functionalized Python code, users can wrap their functions using simple one-line Python decorators. The task decorator is called an electron. The electron decorator simply turns the function into a dispatchable task. Likewise, the workflow decorator is called a lattice. The lattice decorator turns a function composed of electrons into a manageable workflow.
@ct.electron
def task(x):
return x + 1
@ct.lattice
def workflow(x):
return task(x) + task(x + 1)
When the user is ready to run a workflow, they “dispatch” it to the Covalent server using a one-line invocation:
dispatch_id = ct.dispatch(workflow)(x=1)
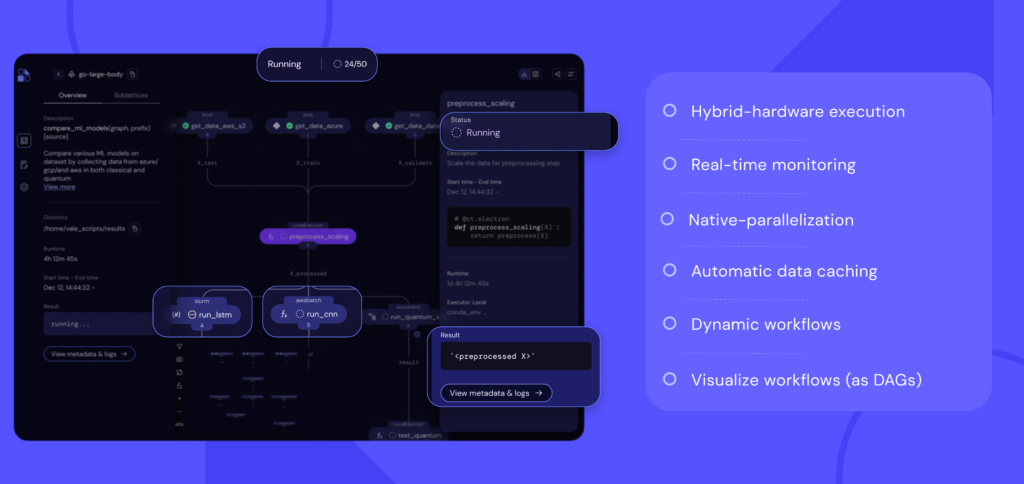
and the instance of a workflow, called a dispatch, is created with a unique ID. Users can navigate to the browser-based user-interface to immediately view the workflow graph as well as all of its metadata, including partial results, benchmarking information, source code, and even where each task ran.
Nested Workflows with Sublattices
When users are suitably satisfied that a workflow is running smoothly, they can again transform the workflow into a task within a higher-order workflow by making it a “sublattice”. Sublattices are simply lattices that are transformed into electrons, making them eligible to become components in other workflows. Continuing the example from above, we see creating a sublattice is as simple as inserting an electron decorator on top of a lattice:
@ct.electron
@ct.lattice
def workflow(x):
return task(x) + task(x + 1)
or use a shorthand syntax to transform an existing lattice into an electron:
sublattice = ct.electron(workflow)
Sublattices are then used within a lattice as if they were regular electrons:
@ct.lattice
def higher_order_workflow(x):
sum = 0
for value in [0, 0.25, 0.5]:
sum += sublattice(value)
return sum
This feature allows users to compose experiments while retaining granular control and understanding of underlying components.
Dynamic Workflows with Sublattices
Using the sublattice construct, users can also construct dynamic workflows — workflows whose exact structure is only determined at runtime. This powerful feature allows users to construct complex flows while still being able to visualize task dependencies:
@ct.electron
@ct.lattice
def dynamic_portion(condition, x):
if condition:
return task(x)
else:
return 0
@ct.electron
def get_condition(x):
return x > 0
@ct.lattice
def dynamic_workflow(x)
return dynamic_portion(get_condition(x), x)
Deploying Workflows to the Cloud and Beyond
At present, all of these tasks and workflows run directly on a user’s local computer in a locally deployed Dask cluster. However, it is straightforward to use Covalent’s executor plugins to route tasks to various remote backends. For instance, users with an AWS account may wish to send an intensive training task to a GPU-based instance on AWS Batch. One of the above tasks can be modified with just a single line of code to support this pattern:
# pip install 'covalent-aws-plugins[batch]'
batch_executor = ct.executors.AWSBatchExecutor(
batch_queue = "test-queue",
vcpu = 8,
memory = 32,
num_gpus = 4,
time_limit = 36000 # 10 hours
)
# @ct.electron # Using this instead reverts to local execution
@ct.electron(executor=batch_executor) # This ports to the cloud!
def task(x):
return x + 1
This demonstrates a key differentiating feature of Covalent — users can offload jobs to one or more cloud providers all from the comfort of a Jupyter notebook. While many popular cloud-based executors, such as AWS Batch, Lambda, and ECS are already available, and users can design multicloud experiments using the Kubernetes executor, we provide even further support for customization with the Executor Plugin Template. This provides a strong starting point for users to design their own custom plugins for Covalent.

Managing Runtime Environments and Data Dependencies
Yet, a key challenge of distributed computing also involves managing data pipelines and compute environments. Covalent also allows users to flexibly deploy tasks with custom runtime and data requirements with ease:
@ct.electron(
deps = ct.DepsPip(packages=["numpy", "torch", "pycuda"]),
files = [ct.fs.FileTransfer(
"/home/user/data.zip",
"s3://my-bucket/data.zip",
strategy = ct.fs_strategies.S3()
)],
executor = batch_executor
)
def task(x):
import numpy
return np.zeros(x)
This task demonstrates users can both specify runtime dependencies as well as dependent files for a task which runs on the cloud using AWS Batch. Not only are such features a convenience, but they provide a powerful means of conveying experiments across teams so that they remain exactly reproducible now and many months down the road.
Since Covalent itself is written in Python, all of the familiar Python packages are compatible out-of-the-box with Covalent, regardless of where tasks run. For instance, one can directly use pytorch or tensorflow on remote instances without any additional modifications. Further, we also provide support for tasks written in other languages such as C/C++ and Bash, enabling hybrid-language experiments. This hybrid-language support is even relevant in the context of Python itself, where certain tasks may depend on different versions of Python or otherwise have conflicting requirements.

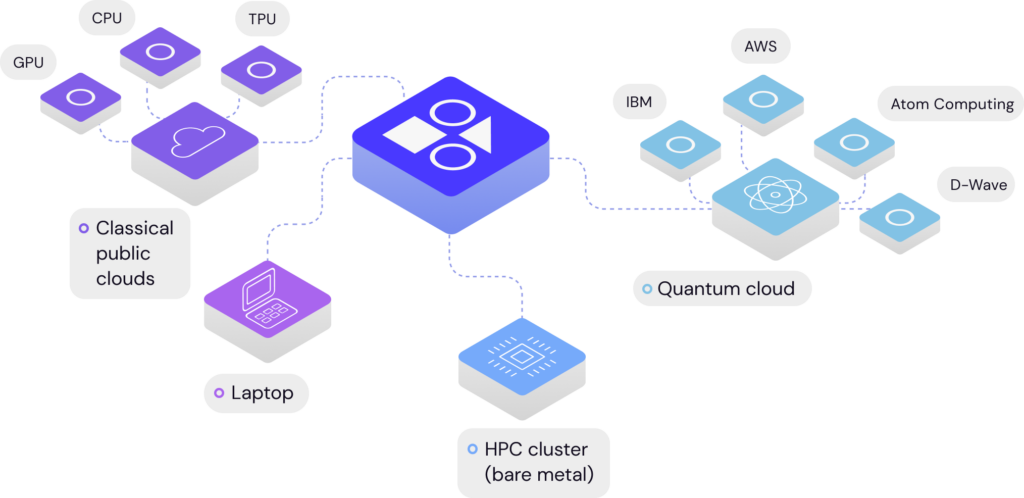
As shown in the image above, Covalent can be used in combination with a variety of other software tools in the software computing stack, because it operates at a layer above other packages. Other distributed computing packages, such as joblib and pycuda, are examples of Python tools which can be leveraged to parallelize machine learning applications over multiple cores. Likewise, tools such as Dask and PySpark can be leveraged to distribute applications across multiple machines within a compute cluster. Covalent operates at a layer above such tools, in what we describe as the “distributed workflow” layer, where a users’ primary focus is on rapid iteration, distributed computation, and experiment management. With Covalent, users are empowered to design and distribute workflows with ease, reproduce and scale experiments instantly, and ultimately spend more time producing novel research.
Users and teams interested in learning more about Covalent can view the source code on GitHub, join the Covalent Slack channel, follow us on Twitter, or reach out for commercial and enterprise use cases at contact@agnostiq.ai. If you like what we’re doing, please show your support by starring our repository.