Build Stock Trading AI Agents with Reinforcement Learning, FinRL, and Covalent
In the example that follows, we will utilize reinforcement learning to build a trading bot (inspired by the FinRL project) and use Covalent Cloud to arbitrarily scale, parallelize, and batch-execute our code on state-of-the-art hardware. Along the way, we’ll illustrate the simple and natural interface that Covalent Cloud provides, as well as several of its key features that make cloud computing more accessible than ever.
Developing with Covalent
Let’s take a brief moment review the key concepts. The Covalent SDK is a Python framework that consists of three main components:
These components let you define complex workflows in a lightweight and non-destructive manner, with minimal and non-intrusive changes to experimental code.
Reinforcement Learning and Finance
Reinforcement learning (RL) is a subset of machine learning that focuses on training an intelligent agent to make decisions in a dynamic environment, aiming to maximize cumulative reward. The agent learns to navigate the environment through trial and error, with the ultimate goal of developing optimal behaviour. Feedback from the environment is provided to the agent in the form of rewards, i.e., quantifiable values that indicate the success or failure of the agent’s actions.
In the realm of finance and trading, the environment aims to capture the stock market, while the agent represents the trader. The trader engages in market transactions, and to train a reinforcement learning-based agent, historical stock market data is utilized. It is assumed that the trading agent has no influence on the stock market prices.
The process of training a reinforcement learning bot for trading involves three stages:
- Downloading and partitioning data into training and test sets.
- Training agents by simulating the stock market using training data.
- Evaluating agent performance using test data.
Algorithms such as Deep Deterministic Policy Gradient (DDPG) and Advantage Actor Critic (A2C) are typically used to train the reinforcement learning agent.
Obtaining Financial Data
The Yahoo Finance library serves as the data source, allowing users to specify date ranges and stocks of interest. A comprehensive guide on utilizing the Yahoo financial API is available here.
from finrl.meta.preprocessor.yahoodownloader import YahooDownloader
def download_data(start_date='2009-01-01', end_date='2020-07-01'):
return YahooDownloader(
start_date=start_date, end_date=end_date,
ticker_list=['AAPL', 'AMZN']
).fetch_data()Once stock prices are acquired, the data undergoes transformation to derive financial indicators such as Moving Average Convergence/Divergence (MACD), Relative Strength Index (RSI), Commodity Channel Index (CCI). Subsequently, the data is divided into training and test sets along the time dimension, ensuring that the training data precedes the test data.
Training Agents
We begin by outlining a state space and an action space. The action space enumerates the possible actions that our agents can undertake. In our scenario, the size of the action space is contingent on the quantity of stocks that can be purchased at each time step. Meanwhile, the state space incorporates financial indicators alongside stock prices. Initially, we set up the environment, followed by the instantiation and training of an agent within that environment.
from finrl.config import INDICATORS
from finrl.meta.env_stock_trading.env_stocktrading import StockTradingEnv
from finrl.agents.stablebaselines3.models import DRLAgent
def train_rl_model(
df, rl_algorithm='ddpg',
model_kwargs={'device': 'cuda:0', 'batch_size': 2048}
):
stock_dimension = len(df.tic.unique())
state_space = 1 + 2 * stock_dimension + len(INDICATORS) * stock_dimension
buy_cost_list = sell_cost_list = [0.001] * stock_dimension
num_stock_shares = [0] * stock_dimension
env_kwargs = {
"hmax": 100,
"initial_amount": 1000000,
"num_stock_shares": num_stock_shares,
"buy_cost_pct": buy_cost_list,
"sell_cost_pct": sell_cost_list,
"state_space": state_space,
"stock_dim": stock_dimension,
"tech_indicator_list": INDICATORS,
"action_space": stock_dimension,
"reward_scaling": 1e-4
}
trading_env = StockTradingEnv(df=df, **env_kwargs)
env_train, _ = trading_env.get_sb_env()
agent = DRLAgent(env=env_train)
model_rl = agent.get_model(rl_algorithm, model_kwargs=model_kwargs)
trained_agent = agent.train_model(
model=model_rl, tb_log_name="a2c",
total_timesteps=10000
)Here, we train a DDPG agent using the stable baselines library. The model_kwargs argument of the above function lets us pass additional parameters of the DDPG agent.
Evaluating Performance
We employ backtesting to evaluate performance, assessing the trading agent on unseen data. Given the complete separation of testing and training environments, adjustments can be made to the testing environment with additional parameters; for example, by introducing a turbulence_threshold. This threshold simulates situations where all stocks are sold due to market instability, as typically measured with an indicator like the Volatility Index (VIX). To gauge your algorithm’s performance against the market, a comparison can be drawn against the Dow Jones Industrial Average (DJI).
def backtest(test_data, trained_model):
e_trade_gym = StockTradingEnv(
df=test_data, turbulence_threshold=70,
risk_indicator_col='vix', **env_kwargs
)
df_account_value, df_actions = DRLAgent.DRL_prediction(
model=trained_model,
environment=e_trade_gym
)
return (df_account_value.set_index(df_account_value.columns[0]))Workflow
Before we can define and execute a workflow, we define a Covalent Cloud Environment with all required dependencies. Some dependencies are installed via conda, such as swig, and others via pip.
cc.create_env(
name="finrl2",
conda={
"channels": ["conda-forge", "defaults"],
"dependencies": [
"python=3.10", "gcc", "gxx", "cxx-compiler", "swig"
]
},
pip=[
"numpy==1.23.5",
"git+https://github.com/AI4Finance-Foundation/FinRL.git",
"stable-baselines3==2.2.1"
],
wait=True, # wait for environment to be ready
)We now consolidate the described steps into a single Covalent workflow for quick iteration, modification, and execution. Two executors are set up: one for GPU and another for CPU usage. The GPU executor handles the computationally heavy training step, while backtesting occurs on the CPU to save resources.
import covalent as ct
import covalent_cloud as cc
gpu_executor = cc.CloudExecutor(
num_gpus=1, env="fin-rl", gpu_type="v100",
memory=16384, num_cpus=4,
)
@ct.electron(executor=gpu_executor)
def train_rl_model(train_data, rl_algorithm='ddpg', model_kwargs={}):
...
cpu_executor = cc.CloudExecutor(env="fin-rl", num_cpus=4, memory=16384)
@ct.electron(executor=cpu_executor)
def backtest(test_data, trained_model):
...
@ct.electron(executor=cpu_executor)
def get_dji_data(start_date, end_date):
...For convenience, our lattice function (workflow()) will include an argument called algorithm_params, which specifies the training hyperparameters.
@ct.lattice(workflow_executor=large_cpu_exec, executor=large_cpu_exec)
def workflow(
train_start_date, train_end_date, test_start_date, test_end_date,
algorithm_params={}
):
train_data, test_data = download_stock_data(
train_start_date, test_end_date
)
results = []
for algorithm in algorithm_params.keys():
trained_model = train_rl_model(
train_data, algorithm, algorithm_params.get(algorithm, {})
)
result = backtest(trained_model, test_data)
result.columns = [algorithm]
results.append(result)
results.append(get_dji_data(test_start_date, test_end_date))
image_plot = plot_results(results)
ct.wait(image_plot, results)
return image_plot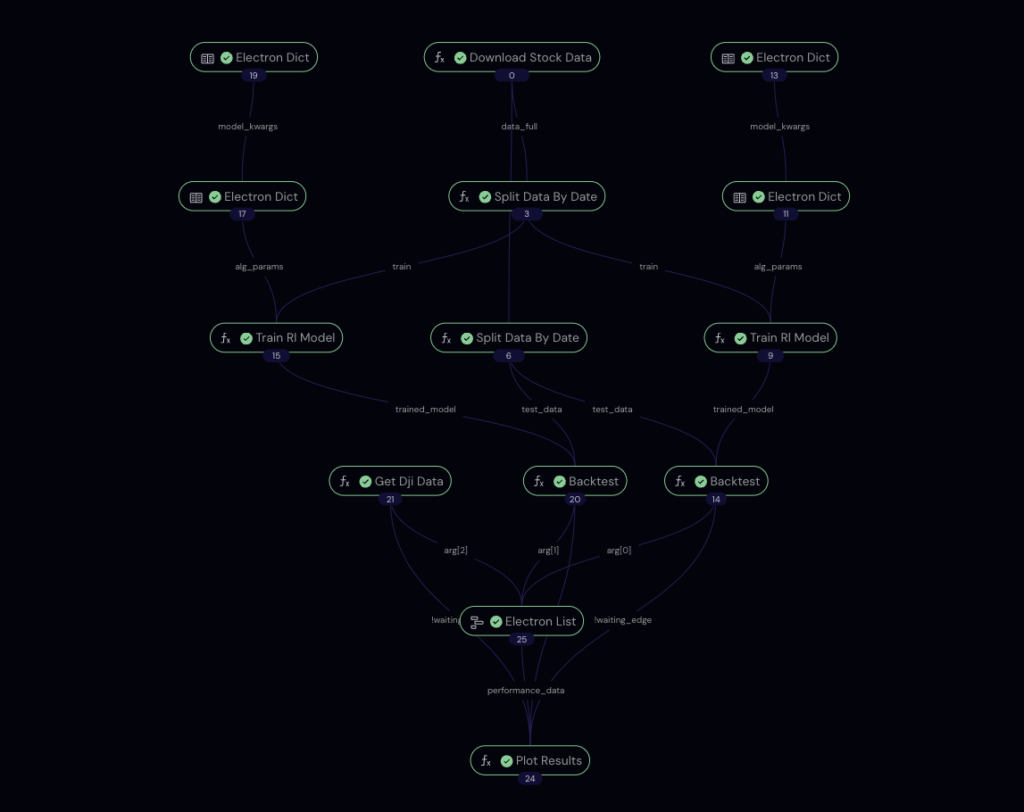
Results
Using the described RL method, the trained agent is observed to outperform the market, taking the Dow Jones Index as a benchmark. In a simulation starting with $1 million, the DDPG-trained agent ended up with $1.45 million, compared to $1.39 million from the DJI. However, another RL agent trained using PPO did not perform as well, finishing with approximately $1.3 million, which is $0.09 million less than the DJI.
Comparing the training time of the same agent on the CPU vs. the GPU, we observed times of 11 and 18 minutes, respectively, for an agent taking 50,000 steps. This difference increases with the number of steps, especially for computationally intensive algorithms such as DDPG.
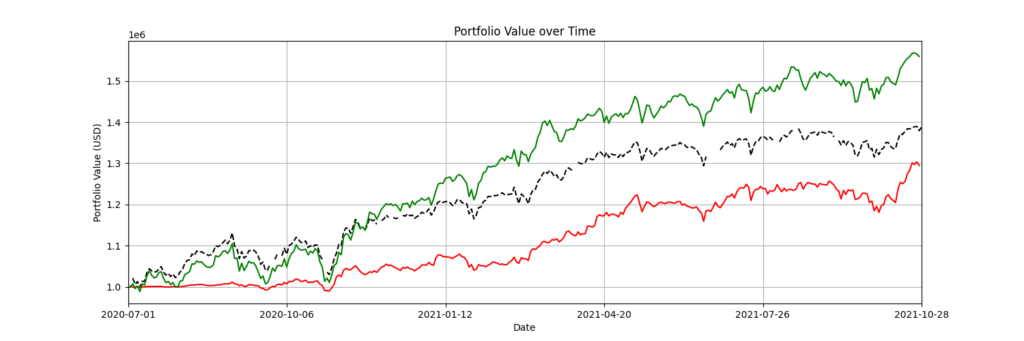
To achieve these results, we used Covalent to seamlessly switch between the GPU and CPU backends by specifying different executors for the various tasks (electrons) that comprised our workflow. More specifically, GPU backends were used for the computationally expensive training step, with the remainder delegated to CPU backends; providing savings in both time and cost.
Conclusion
We’ve illustrated the construction and experimentation of a reinforcement learning stock trading agent using Covalent and FinRL. FinRL’s strengths lie in establishing a trading environment and its seamless integration with advanced reinforcement learning libraries, fostering the development of sophisticated trading agents. Covalent complements this by streamlining modifications and iterations, tracking final and intermediate results, and allowing users to effectively experiment with diverse hyperparameters, all while making optimal use of compute and storage resources.