Covalent Function Serve: A Simpler Way to Develop Any AI Application Imaginable

Since launching Covalent in January of 2022, our mission has been to put the power of accelerated computing at the fingertips of every developer. We built Covalent to empower users to easily scale jobs from a notebook to any major public cloud or specialized GPU cloud – even a supercomputer like Frontier – entirely in Python, and without managing any of the underlying infrastructure or cloud operations.
Today, we’re taking the next step in the platform’s evolution with the release of Covalent Function Serve – Covalent’s new inference service. Now, users can effortlessly train, fine-tune, host, and serve AI models entirely within the Covalent platform and with only a few additional lines of Python. Covalent’s serverless architecture will orchestrate all of the underlying infrastructure required to efficiently run and scale the application. All with the same high-level and intuitive abstractions that Covalent users have become accustomed to.
Deploying models is just the start of what’s possible. Covalent has workflow capabilities that can execute tasks in parallel or in sequence as well as manage the interactions between them regardless of how complex. As a result, Covalent is ideal for creating applications such as multi-agent AI, digital twins, and scientific simulations – and any other systems that utilize multiple inference services or compute nodes which interact with one another. The combination of infrastructure abstraction and workflow orchestration unleashes developer creativity to build any AI application imaginable with unprecedented speed and agility.
With the addition of Covalent Function Serve, users can now:
- Train, fine-tune, and deploy any open source or proprietary AI model from a single Python notebook
- Create and easily manage multi-agent AI applications with complex agent interactions, even when deployed across different hardware/cloud environments
- Productionize and scale any application or workflow that leverages accelerated computing through simple API integration
This can all be accomplished without users having to manage any of the underlying infrastructure, making Covalent the all-in-one backend solution for everything from chemistry simulations to AI development.
Check out the tutorials below to see Covalent + Function Serve in action:
- Deploying Llama 3 inference for text generation
- Fine-tuning and validating LLMs with Covalent
- Building a Multi-Agent Prompt Refining Application
- Build your own synthetic data generator with foundational models
Keep on reading to learn more about what this release means for Covalent.
Serve Any AI Model
Deploying an AI model is simple. Users can focus on the AI itself, while Covalent handles the underlying infrastructure, making intelligent scaling, hardware optimization, and serving AI effortless. If they choose to dig deeper, users can control everything from model tokenization to memory utilization.
See the example below for deploying a production-ready Llama 70B-based chatbot running on NVIDIA H100s, just by adding three additional lines of code.

Combine Fine-tuning and Inference with Workflows
Combining inference as a part of more complex workflows is also supported by Covalent. You can even chain together multiple deployments with complex dependencies. The example below shows how to download data, fine-tune multiple models, and deploy every one of them in parallel with little to no extra work – they each utilize their own compute from H100 GPUs for training, to L40 GPUs for inference, and CPUs for data pre-processing.
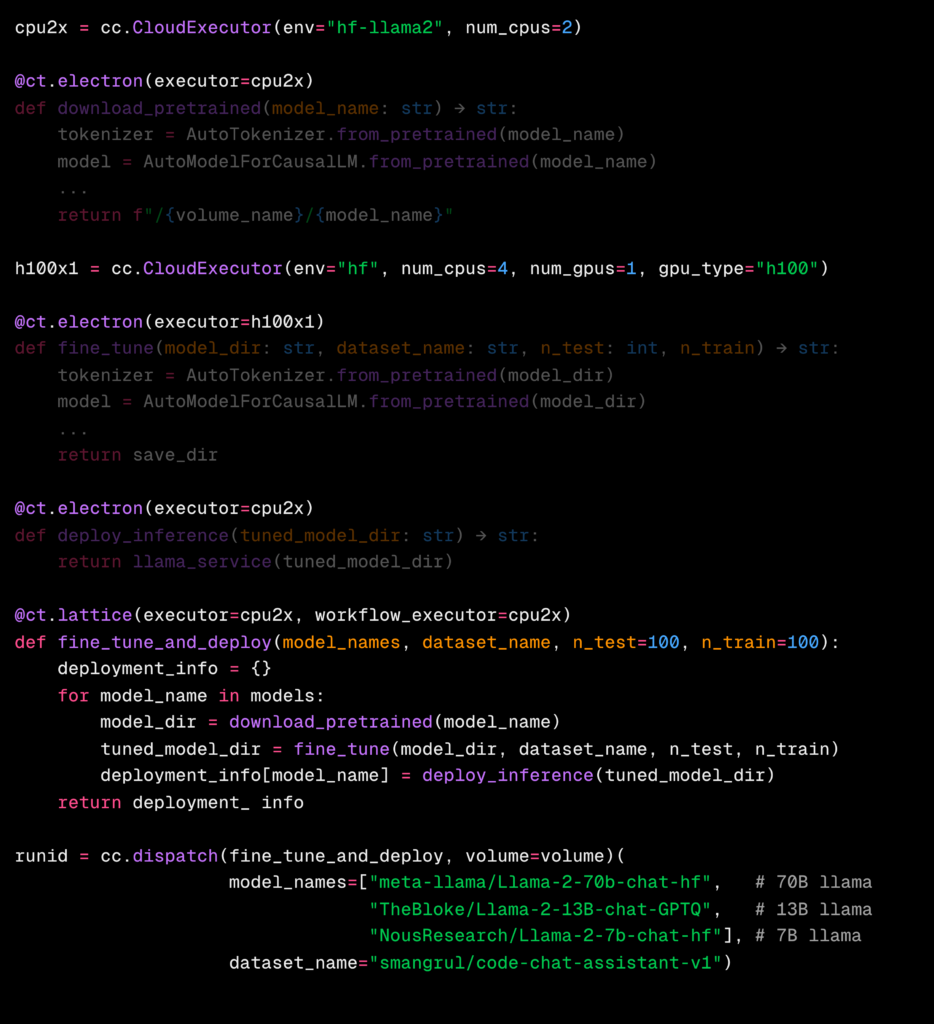
Complex Multi-Agent AI, Simplified
Covalent lets users express complex dependencies as a seamless Python workflow, easily supporting the creation and deployment of multi-agent AI systems. For example, a coding assistant can create agents for roles such as CTO, product manager, coder, and reviewer, and employ different agents through the stages of requirements definition, programming, and testing. Each AI agent can be “fine-tuned” and deployed on their own hardware and environment based on model size and usage.
See the tutorial on creating a multi-agent prompt refining application that uses multiple specialized agents to generate a detailed, embellished prompt from simple user input, that ultimately leads to a richer LLM text output.
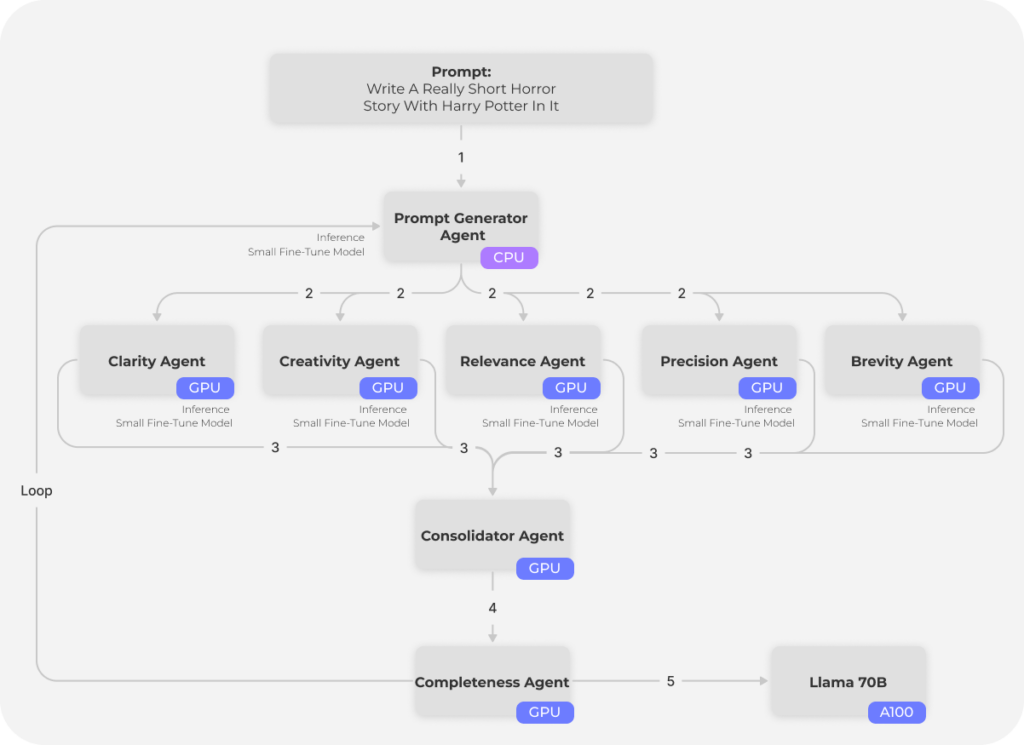
Users no longer need to construct convoluted infrastructure diagrams or be burdened with coordinating activities manually. Covalent provides a visual overview of the AI system, making experimentation, scaling, and optimization easier than ever.
Learn More
Try it out for yourself by signing up for Covalent Cloud today. It’s free to start and includes up to 30 hours of GPU compute credits. You can read more about the platform in our docs and by checking out our tutorials.